Публикации
 Разное
Разное
Распределенные вычисления на FreePascal под Windows. |
07.12.2005 Илья Аввакумов |
Оглавление
- Введение. О чем эта статья.
- Установка и настройка MPICH.
- Простейшая MPI-программа на FreePascal.
- Запуск MPI-программы.
- Более сложные программы.
- Полезные ссылки.
Введение. О чем эта статья.
Статья посвящена вопросу написания распределенных (параллельных) вычислений с использованием компилятора FreePascal (использовалась версия 2.0.1)
Проблема параллельных вычислений заинтересовала меня совсем не потому что это сейчас модно. Столкнулся с задачей, когда надо было сформировать (для дальнейнего анализа) большой массив данных. Хотелось уменьшить время вычислений имеющимися средствами. Оказывается, организовать параллельные вычисления с использованием моего любимого компилятора — вполне решаемая задача.
Стандартом для параллельных приложений для многопроцессорных вычислительных систем де-факто является MPI.
Идея MPI-программы такова: параллельная программа представляется в виде множества взаимодействующих (посредством коммуникационных процедур MPI) процессов.
Параллельные вычисления требуют
- Разделения процессов
- Взаимодействия между ними
MPI (Message Passing Interface) — стандарт на программный инструментарий для обеспечения связи между ветвями параллельного приложения.
В этой статье рассматривается MPICH (MPI CHameleon), свободно распространяемая реализация MPI. Использовалась версия MPICH 1.2.5 для Windows.
Установка и настройка MPICH.
MPICH для Windows требует
- Windows NT4/2000/XP ( Professional или Server). Под Win9x/ME работать не станет!
- Сетевое соединение по протоколу TCP/IP между машинами.
Сразу обговорю, что все примеры тестировались на двух машинах, объединенных в локальную сеть. Один компьютер (сетевое имя ILYA) — мой, а второй (сетевое имя EKATERINA) — жены.
Установка.
Компьютеры, участвующие в вычислениях, назовем кластером. MPICH должен быть установлен на каждом компьютере в кластере.
Для установки нужно
- Скачать mpich.nt.1.2.5.src.exe (5278 Кб) или mpich.nt.1.2.5.src.zip (5248 Кб)
Либо с официальной страницы MPICH http://www.mcs.anl.gov/mpi/mpich/download.html
Либо с ftp сервера ftp.mcs.anl.gov/pub/mpi/nt.
- Если запустить exe файл, то после распаковки запустится интерактивная программа установки MPICH. Чтобы не утомлять себя выбором устанавливаемых компонент, удобнее установить MPICH в неинтерактивном режиме.
- Для этого
- а. Разархивируйте содержимое в общую папку (например, \\ILYA\common)
- b. Отредактируйте файл setup.iss
- c. Строка
szDir=C:\Program Files\MPICH
определяет каталог, куда установится MPICH. Это расположение можно изменить.- d. Строки
Component-count=7 Component-0=runtime dlls Component-1=mpd Component-2=SDK Component-3=Help Component-4=SDK.gcc Component-5=RemoteShell Component-6=Jumpshot
определяют число устанавливаемых компонент.- Для главного компьютера (откуда запускается главный процесс) подходящие опции таковы
Component-count=4 Component-0=runtime dlls Component-1=mpd Component-2=SDK Component-3=Help
- Для простого компьютера (которому отводится только роль вычислителя) число компонент может быть сокращено до двух.
Component-count=2 Component-0=runtime dlls Component-1=mpd
- На каждом компьютере кластера выполнить команду установки в неинтерактивном режиме. В моем случае запуск программы установки таков:
>\\ILYA\common\setup -s -f1\\ILYA\common\setup.iss
После установки на каждом компьютере должна запуститься служба mpich_mpd (MPICH Daemon (C) 2001 Argonne National Lab). (смотрите рисунок)
Если был установлен компонент SDK (что необходимо сделать на том компьютере, откуда будет производиться запуск программ), то в каталоге MPICH (прописанном в пункте szDir) присутствуют подкаталоги SDK и SDK.gcc. Содержимое этих каталогов — библиотечные и заголовочные файлы для языков C, С++ и Fortran.
Каталог SDK предназначен для компиляторов MS VC++ 6.x и Compaq Visual Fortran 6.x, а каталог SDK.gcc — для компиляторов gcc и g77.
Настройка
Настройку можно осуществить с помощью простых утилит, имеющихся в дистрибутиве.
Остановимся подробнее на каталоге mpd\bin в директории MPICH. Содержимое каталога:
| mpd.exe | исполняемый файл службы mpich_mpd | нужна |
| MPIRun.exe | файл, осуществляющий запуск каждой MPI-программы. | нужна |
| MPIRegister.exe | программа для шифрования паролей при обмене данными по LAN. | иногда полезна |
| MPDUpdate.exe | программа для обновления библиотек MPI | не нужна |
| MPIConfig.exe | программа настройки хостов в кластере | не нужна |
| guiMPIRun.exe | GUI версия mpirun. | не нужна |
| MPIJob.exe | программа для управления MPI-процессами | не нужна |
| guiMPIJob.exe | GUI версия mpijob.exe | не нужна |
Использование команд mpirun и mpiregister ждет нас впереди. Чтобы удостовериться, что службы MPICH, работающие на разных компьютерах, взаимодействуют должным образом, можно воспользоваться утилитой MPIconfig. Для этого следует
- Запустить MPIConfig.exe (можно воспользоваться ссылкой в главном меню, она там должна быть)
- Нажать на кнопку "Select"
- В появившемся окне выбрать пункт меню "Action"—"Scan hosts"
- Напротив имени каждой машины должна загореться пиктограмма "MPI" ( примерно вот так)
Модуль mpi на FreePascal.
Все вышеописанное относилось к установке собственно MPICH. Для того, чтобы прикрутить библиотеки MPICH к FreePascal, следует еще немножко поработать.
Cледует воспользоваться динамической библиотекой mpich.dll, которая располагается в системном каталоге (копируется туда при установке MPICH).
- Скачать модуль FreePascal, реализующий функции этой динамической библиотеки. Файл mpi.pp скачать zip-архив (10 КБ)
- Для использования модуля mpi следует просто скопировать файл mpi.pp в каталог, где FreePascal ищет модули (unit searchpath).
Модуль написан с использованием утилиты h2pas.exe и заголовочных файлов *.h из SDK\Include.
Простейшая MPI программа на FreePascal.
Во именах всех функциях библиотеки MPICH используется префикс MPI_. Возвращаемое значение большинства функций — 0, если вызов был успешным, а иначе — код ошибки.
Основные функции.
Основные функции MPI, с помощью которых можно организовать параллельное вычисление
| 1 | MPI_Init | подключение к MPI |
| 2 | MPI_Finalize | завершение работы с MPI |
| 3 | MPI_Comm_size | определение размера области взаимодействия |
| 4 | MPI_Comm_rank | определение номера процесса |
| 5 | MPI_Send | стандартная блокирующая передача |
| 6 | MPI_Recv | блокирующий прием |
Утверждается, что этого хватит. Причем первые четыре функции должны вызываться только один раз, а собственно взаимодействие процессов — это последние два пункта.
Описание функций, осуществляющих передачу, оставим на потом, а сейчас рассмотрим описание функций инициализации/завершения
function MPI_Init( var argc : longint;
var argv : ppchar) : longint;
Инициализация MPI. Аргументы argc и argv — переменные модуля system, определяющие число параметров командной строки и сами эти параметры, соответственно.
При успешном вызове функции MPI_Init создается коммуникатор ( область взаимодействия процессов), под именем MPI_COMM_WORLD.
function MPI_Comm_size( comm : MPI_Comm;
var nump : longint) : longint;
Определяет число процессов, входящих в коммуникатор comm.
function MPI_Comm_rank( comm : MPI_Comm;
var proc_id : longint) : longint;
Определяется ранг процесса внутри коммуникатора. После вызова этой функции все процессы, запущенные загрузчиком MPI-приложения, получают свой уникальный номер (значение возвращаемой переменной proc_id у всех разное). После вызова функции MPI_Comm_rank можно, таким образом, назначать различным процессам различные вычисления.
function MPI_Finalize : longint;
Завершает работу с MPI.
Порядок вызова таков:
MPI_Init— подключение к MPIMPI_Comm_size— определение размера области взаимодействияMPI_Comm_rank— определение номера процесса- Далее идет любая совокупность команд обмена (передача, прием, и тп)
MPI_Finalize— завершение работы с MPI
Простейшая MPI программа такова.
test.pas
uses mpi;
var namelen, numprocs, myid : longint;
processor_name : pchar;
begin
MPI_Init( argc, argv);
MPI_Comm_size( MPI_COMM_WORLD, numprocs);
MPI_Comm_rank( MPI_COMM_WORLD, myid);
GetMem( processor_name, MPI_MAX_PROCESSOR_NAME+1); // константа MPI_MAX_PROCESSOR_NAME равна 256
namelen := MPI_MAX_PROCESSOR_NAME;
MPI_Get_processor_name( processor_name, namelen);
Writeln('Hello from ',myid,' on ', processor_name);
FreeMem(processor_name);
MPI_Finalize;
end.
Здесь, как видно, никакого обмена нет, каждый процесс только "докладывает" свой ранг.
Для наглядности выводится также имя компьютера, где запущен каждый процесс. Для его определения используется функция MPI_Get_processor_name.
function MPI_Get_processor_name( proc_name : Pchar;
var name_len : longint) : longint;
При успешном вызове этой функции переменная proc_name содержит строку с именем компьютера, а name_len — длину этой строки.
После компиляции (с соответствующими опциями)
>fpc -dRELEASE [-Fu<каталог, где размещен файл mpi.pp>] test.pas
должен появиться исполняемый файл test.exe, однако рано радоваться. Запуск этого exe-файла не есть запуск параллельной программы.
Запуск MPI-программы.
Запуск MPI-программы осуществляется с помощью загрузчика приложения mpirun. Формат вызова таков:
>mpirun [ключи mpirun] программа [ключи программы]
Вот некоторые из опций команды mpirun:
| -np x |
| запуск x процессов. Значение x может не совпадать с числом компьютеров в кластере. В этом случае на некоторых машинах запустится несколько процессов. То, как они будут распределены, mpirun решит сам (зависит от установок, сделанных программой MPIConfig.exe) |
| -localonly x |
| -np x -localonly |
| запуск x процессов только на локальной машине |
| -machinefile filename |
| использовать файл с именами машин |
| -hosts n host1 host2 ... hostn |
| -hosts n host1 m1 host2 m2 ... hostn mn |
| запустить на n явно указанных машинах. Если при этом явно указать число процессов на каждой из машин, то опция -np становится необязательной |
| -map drive: \\host\share |
| использовать временный диск |
| -dir drive:\my\working\directory |
| запускать процессы в указанной директории |
| -env "var1=val1|var2=val2|var3=val3..." |
| присвоить значения переменным окружения |
| -logon |
| запросить имя пользователя и пароль |
| -pwdfile filename |
| использовать указанный файл для считывания имени пользователя и пароля. Первая строка в файле должна содержать имя пользователя, а вторая — его пароль) |
| -nocolor |
| подавить вывод от процессов различным цветом |
| -priority class[:level] |
| установить класс приоритета процессов и, опционально, уровень приоритета. class = 0,1,2,3,4 = idle, below, normal, above, high level = 0,1,2,3,4,5 = idle, lowest, below, normal, above, highest |
| по умолчанию используется -priority 1:3, то есть очень низкий приоритет. |
Для организации параллельного вычисления на нескольких машинах следует
- На каждом компьютере, входящем в кластер, завести пользователя с одним и тем же именем (например, MPIUSER) и паролем (я дал ему пароль "1"), с ограниченными привилегиями.
- На главном компьютере (в моем случае это, разумеется, ILYA) создать сетевую папку (например, COMMON). Следует озаботиться, чтобы пользователь MPIUSER имел к ней полный доступ.
- В той же папке создать файл, содержащий имя пользователя, от чьего имени будут запускаться процессы, а также его пароль. В моем случае содержимое этого файла должно быть таким:
mpiuser 1
Я назвал это файл lgn.
После всех этих действий запуск MPI программы test осуществить можно как
>mpirun -pwdfile \\ILYA\COMMON\lgn -hosts 2 ILYA 1 EKATERINA 1 \\ILYA\COMMON\test.exe
Изменив соответствующие опции, можно запускать различное число процессов. Например
>mpirun -pwdfile \\ILYA\COMMON\lgn -hosts 2 ILYA 3 EKATERINA 3 \\ILYA\COMMON\test.exe
На рисунке виден результат такого вызова. Вывод от различных процессов выделяется различным цветом, поскольку опция -nocolor отключена. Обратите внимание на то, что последовательность номер выводимой строки вовсе не совпадает с номером процесса. Этот порядок будет меняться от случая к случаю.
На этом рисунке запечатлен Диспетчер задач при запуске на компьютере EKATERINA четырех процессов. Установлен приоритет по умолчанию.
Утилита MPIRegister.exe.
Поскольку компьютеры ILYA и EKATERINA объединены в локальную сеть, у меня нет никаких проблем с безопасностью. Пароль для пользователя mpiuser хранится в открытом виде в файле lgn. Увы, так можно делать далеко не всегда. Если компьютеры, входящие в кластер, являются частью более разветвленной сети, или, более того, используют подключение к Internet, так поступать не просто не желательно, а недопустимо.
В таких случаях следует хранить пароль пользователя, от имени которого будут запускаться процессы, в системном реестре Windows в зашифрованном виде. Для этого предназначена программа MPIRegister.exe.
Опции таковы
| mpiregister |
| Запрашивает имя пользователя и пароль (дважды). После ввода спрашивает, сделать ли установки постоянными. При ответе 'yes' данные будут сохранены на диске, а иначе — останутся в оперативной памяти и при перезагрузке будут утеряны. |
| mpiregister -remove |
| Удаляет данные о пользователе и пароле. |
| mpiregister -validate |
| Проверяет правильность сохраненных данных. |
Запускать mpiregister следует только на главном компьютере. Загрузчик приложения mpirun без опции -pwdfile будет запрашивать данные, сохраненные программой mpiregister. Если таковых не обнаружит, то запросит имя пользователя и пароль сам.
Более сложные программы.
Сейчас, когда заработала простейшая программа, можно начать осваивать функции обмена данными — именно то, что позволяет осуществить взаимодействие между процессами.
Функции двухточечного обмена.
Блокирующая передача (прием) — означает, что программа приостанавливает свое выполнение, до тех пор, пока передача (прием) не завершится. Это гарантирует именно тот порядок выполнения операций передачи (приема), который задан в программе.
Блокирующая передача осуществляется с помощью функции MPI_Send.
function MPI_Send( buf : pointer;
count : longint;
datatype : MPI_Datatype;
destination : longint;
tag : longint;
comm : MPI_Comm) : longint;
Осуществляет передачу count элементов указанного типа процессу под номером destination.
buf | — адрес первого элемента в буфере передачи |
count | — количество передаваемых элементов в буфере |
datatype | — MPI-тип этих элементов |
destination | — ранг процесса-получателя (принимает значения от нуля до n-1, где n — полное число процессов) |
tag | — тег сообщения |
comm | — коммуникатор |
В качестве MPI-типа следует указать один из нижеперечисленных типов. Большинству базовых типов паскаля соответствует свой MPI-тип. Все они перечислены в следующей таблице. Последний столбец указывает на число байт, требуемых для хранения одной переменной соответствующего типа.
MPI_CHAR | shortint | 1 |
MPI_SHORT | smallint | 2 |
MPI_INT | longint | 4 |
MPI_LONG | longint | 4 |
MPI_UNSIGNED_CHAR | byte | 1 |
MPI_UNSIGNED_SHORT | word | 2 |
MPI_UNSIGNED | longword | 4 |
MPI_UNSIGNED_LONG | longword | 4 |
MPI_FLOAT | single | 4 |
MPI_DOUBLE | double | 8 |
MPI_LONG_DOUBLE | double | 8 |
MPI_BYTE | untyped data | 1 |
MPI_PACKED | составной тип | - |
Переменная tag — вспомогательная целочисленная переменная.
MPI-тип MPI_PACKED используется при передаче данных производных типов (сконструированных из базовых типов). Их рассмотрение выходит за рамки данной статьи.
Функция MPI_Recv реализует блокирующий прием данных.
function MPI_Recv( buf : pointer;
count : longint;
datatype : MPI_Datatype;
source : longint;
tag : longint;
comm : MPI_Comm;
var status : MPI_Status) : longint;
buf | — начальный адрес буфера приема |
count | — максимальное количество принимаемых элементов в буфере |
datatype | — MPI-тип этих элементов |
source | — ранг источника |
tag | — тег сообщения |
comm | — коммуникатор |
status | — статус обмена |
Эта функция осуществляет запрос на получение данных. При ее вызове процесс будет ожидать поступления данных от процесса под номером source. Если таковой не последует, то это приведет к повисанию программы (тупик). Так что при использовании этих функций следует проявлять бдительность.
Число принятых элементов может быть меньше значения переменной count. Если же посылаемые данные имеют больший размер, то будет выведено предупреждение об обрывании передачи.
Возвращаемая переменная status содержит информацию о передаче. Например, ее можно использовать, чтобы определить фактическое количество принятых элементов. Для этого используется функция MPI_Get_count
function MPI_Get_count(var status : MPI_Status;
datatype : MPI_Datatype;
var count : longint) : longint;
Число фактически принятых элементов — в возвращаемой переменной count.
Использование функций двухточечного обмена.
В следующем примере вычисление значений элементов массива "разводится" по двум процессам
uses mpi;
const num = 10;
var
teg, numprocs, myid : longint;
i : longint;
status : MPI_Status;
z, x : double;
arr : array[0..num] of double;
function f( x : double) : double;
begin
f := sqr(x);
end;
begin
MPI_Init(argc,argv);
teg := 0;
MPI_Comm_size(MPI_COMM_WORLD, numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, myid);
for i := 0 to num do
case myid of
0:
if i mod 2 = 0 then arr[i] := f(1.0*i)
else
begin
MPI_Recv(@x,1,MPI_DOUBLE,1,teg,MPI_COMM_WORLD,status);
arr[i] := x
end;
1:
if i mod 2 = 1 then
begin
z := f(1.0*i);
MPI_Send(@z,1,MPI_DOUBLE,0,teg,MPI_COMM_WORLD);
end;
end; // case statement
if myid = 0 then for i := 0 to num do writeln(i,' ',arr[i]);
MPI_Finalize;
end.
Формируется массив заданного числа элементов так, что элементы с четными номерами рассчитывает процесс с myid=0, а нечетными — с myid=1. Конечно, вместо функции sqr может стоять любая другая. Программа написана, конечно же, в расчете на то, что процессов будет всего два. Поскольку значения myid, отличные от 0 и 1, не используются, процессы с такими номерами будут простаивать.
Улучшить программу, то есть написать такой ее вариант, чтобы использовались все процессы, предоставляю читателю :)
Функции коллективного обмена.
Коллективный обмен данными затрагивает не два процесса, а все процессы внутри коммуникатора.
Простейшими (и наиболее часто используемыми) разновидностями такого вида взаимодействия процессов являются рассылка MPI_Bcast и коллективный сбор данных MPI_Reduce.
function MPI_Bcast( buff : pointer;
count : longint;
datatype : MPI_Datatype;
root : longint;
comm : MPI_Comm) : longint;
buf | — адрес первого элемента буфера передачи |
count | — максимальное количество принимаемых элементов в буфере |
datatype | — MPI-тип этих элементов |
root | — ранг источника рассылки |
comm | — коммуникатор |
Функция MPI_Bcast реализует "широковещательную передачу". Один процесс ( главный или root процесс) рассылает всем (и себе, в том числе) сообщение длины count, а остальные получают это сообщение.
function MPI_Reduce( buf : pointer;
result : pointer;
count : longint;
datatype : MPI_Datatype;
operation : MPI_Op;
root : longint;
comm : MPI_Comm) : longint;
buf | — адрес первого элемента буфера передачи |
count | — количество элементов в буфере передачи |
datatype | — MPI-тип этих элементов |
operation | — операция приведения |
root | — ранг главного процесса |
comm | — коммуникатор |
Функция MPI_Reduce выполняет операцию приведения над массивов данных buf, полученным от всех процессов, и пересылает результат в result одному процессу (ранг которого определен параметром root).
Как и функция MPI_Bcast, эта функция должна вызываться всеми процессами в заданном коммуникаторе, и аргументы count, datatype и operation должны совпадать.
Имеется 12 предопределенных операций приведения
MPI_MAX | максимальное значение |
MPI_MIN | минимальное значение |
MPI_SUM | суммарное значение |
MPI_PROD | значение произведения всех элементов |
MPI_LAND | логическое "и" |
MPI_BAND | побитовое "и" |
MPI_LOR | логическое "или" |
MPI_BOR | побитовое "или" |
MPI_LXOR | логическое исключающее "или" |
MPI_BXOR | побитовое исключающее "или" |
MPI_MAXLOC | индекс максимального элемента |
MPI_MINLOC | индекс минимального элемента |
Использование коллективных функций ( вычисление числа 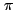 ).
).
Следующая программа демонстрирует вычисление определенного интеграла.
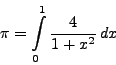
uses mpi;
// паскаль версия файла cpi.c из дистрибутива MPICH
var
i, n, numprocs, myid : longint;
teg : longint;
status : MPI_Status;
startwtime, endwtime : double;
mypi, pimy, h, sum, x : double;
fname : text;
function f( r : double) : double;
begin
f := 4.0/(1 + sqr(r))
end;
begin
MPI_Init(argc,argv);
teg := 0;
MPI_Comm_size(MPI_COMM_WORLD, numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, myid);
n := 0;
if myid=0 then
begin
Assign(fname,'n.in');
{$I-}
Reset(fname);
Readln(fname,n);
Close(fname);
{$I+}
startwtime := MPI_Wtime;
end;
MPI_Bcast( @n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if n<>0 then
begin
h := 1.0/n;
sum := 0.0;
i := myid + 1;
while i <= n do
begin
x := h*( i - 0.5);
sum := sum + f(x);
i := i + numprocs;
end;
mypi := h*sum;
MPI_Reduce( @mypi, @pimy, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if myid = 0 then
begin
writeln('pi is approximately ', pimy, '; error is', abs(pimy-pi));
endwtime := MPI_WTime;
writeln('wall clock ', endwtime-startwtime)
end;
end;
MPI_Finalize;
end.
Файл n.in, содержащий в первой строке число разбиений (чем больше число, тем точнее считается ![]() ) должен присутствовать в том каталоге, где находится исполняемый файл.
) должен присутствовать в том каталоге, где находится исполняемый файл.
Обратите внимание на то, что в этой программе нет case-вилок &mdash все процессы вызывают одни и те же функции.
Полезная функция MPI_Wtime
function MPI_Wtime : double;
возвращает время ( в секундах), прошедшее с некоторого фиксированного момента в прошлом. Гарантируется, что этот фиксированный момент неизменен в течение работы процесса. С помощью этой функции можно отслеживать время вычислений и оптимизировать распараллеливание программы.
В каталоге SDK/Examples также можно найти файл systest.c. Здесь находится версия этой программы, написанная на паскале.
Заключение.
Модуль mpi.pp содержит описание 230 функций MPI. У меня нет никакой возможности перечислить их все, да я и не ставил перед собой такой задачи. Я могу лишь гарантировать, что все функции, которые я использовал в приведенных примерах, работают правильно.
Если же Вам удалось найти (а еще лучше &mdash исправить) какой-либо баг в файле mpi.pp &mdash большая просьба сообщить об этом мне на avva14@mail.ru.
Замеченные мною баги:
- Функции
MPI_Info_c2f,MPI_Info_f2cиMPI_Request_c2f
Что они делают, я не знаю. В текущем модуле mpi.pp эти функции остаются нереализованными.
Благодарности.
Хочу поблагодарить свою супругу за любезно предоставленный компьютер для тестирования своих параллельных приложений.
Также выношу благодарность Шихалеву Ивану, который сильно помог в исправлении неточностей и ошибок первоначальной версии модуля mpi.pp.
Полезные ссылки.
- http://www.mpi-forum.org — сайт, посвященный стандарту MPI.
- http://www-unix.mcs.anl.gov — официальный сайт MPICH.
- http://www.parallel.ru — ведущий русскоязычный сайт по параллельным вычислениям. На форуме будьте осторожны — там люди программируют на Си !
- http://www.parallel.uran.ru/doc/mpi_tutor.html — хороший учебник по MPI для начинающих.
Не могу не порекомендовать также и печатную литературу по этой тематике:
- С. Немнюгин, О. Стесик. Параллельное программирование для многопроцессорных вычислительных систем. "БХВ-Петербург" СПб, 2002.
Основы параллельного программирования изложены в доступной форме, большую часть книги занимает именно описание функций библиотеки MPI. - В.Д. Корнеев. Параллельное программирование в MPI. "Институт компьютерных исследований" М, Ижевск, 2003.
Здесь изложение гораздо более "приземленное", что тоже хорошо, так как описываются (и снабжаются кодом на Си) конкретные алгоритмы, использующие параллельные вычисления.
| FPC | 3.2.2 | release |
| Lazarus | 3.2 | release |
| MSE | 5.10.0 | release |
| fpGUI | 1.4.1 | release |