Если у кого-то есть наработки в этом направлении или желание и время покопать, то велком
Модератор: Модераторы
![]() delphius » 10.06.2023 01:01:10
delphius » 10.06.2023 01:01:10
![]() Снег Север » 10.06.2023 22:14:32
Снег Север » 10.06.2023 22:14:32

![]() delphius » 10.06.2023 23:07:58
delphius » 10.06.2023 23:07:58
Снег Север писал(а):А зачем такой интерфейс в замену формам в обычных проектах - не могу себе представить даже
![]() Снег Север » 11.06.2023 07:57:25
Снег Север » 11.06.2023 07:57:25
![]() delphius » 11.06.2023 10:23:41
delphius » 11.06.2023 10:23:41
Снег Север писал(а):даёт полную унификацию интерфейса
![]() Alex2013 » 11.06.2023 10:34:04
Alex2013 » 11.06.2023 10:34:04
![]() delphius » 11.06.2023 11:37:02
delphius » 11.06.2023 11:37:02
Alex2013 писал(а):а плеер "на HTML5" ваш WebUI потянет?
Alex2013 писал(а):с помощью CEF4
![]() Alex2013 » 11.06.2023 13:07:38
Alex2013 » 11.06.2023 13:07:38
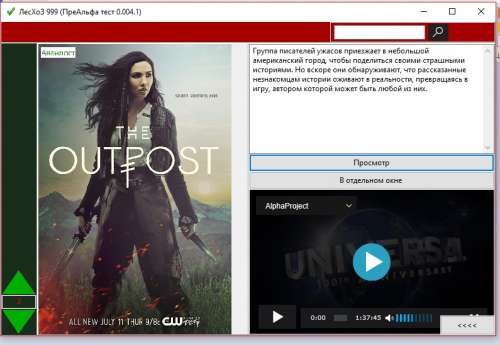

![]() delphius » 11.06.2023 15:01:56
delphius » 11.06.2023 15:01:56
Alex2013 писал(а):или порезали поддержку "древнего IE" на "целевом сайте"
Alex2013 писал(а):Очень интересно буду разбираться ...
Alex2013 писал(а):затолкать CEF4 браузер в DLL
![]() Alex2013 » 11.06.2023 17:19:35
Alex2013 » 11.06.2023 17:19:35
delphius писал(а):Я почитал ветку, но так и не понял конечный сценарий использования, который предполагается? Можно пояснить в двух трех предложениях?
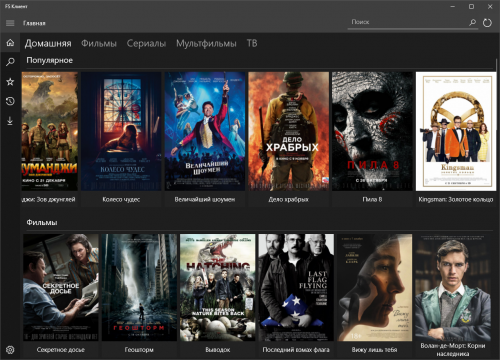


Alex2013 писал(а):Вот бы его еще и на гитхабе увидеть
![]() delphius » 11.06.2023 20:07:55
delphius » 11.06.2023 20:07:55
Alex2013 писал(а):пока что в основном волнует все тот-же запуск плеера с сайтов разнообразных онлайн кинотеатров
Alex2013 писал(а):запустил свой собственный до сих пор сильно "экспериментальный " проект
Alex2013 писал(а):В первую очередь для возможности запуска плеера "в режиме предпросмотра"
Alex2013 писал(а):Ну вы слишком много хотите
![]() Alex2013 » 12.06.2023 14:48:02
Alex2013 » 12.06.2023 14:48:02
. Вторичная проблема, это связывание медиаконтента с основной базой, но она, скорее всего больше техническая (навскидку - парсингом id медиаконтента из ссылок на imdb или кинопоиск) или же, если провайдер один, то вообще без связывания, просто "оборачивая" его сайт путем парсинга и вывода в приложении только необходимых элементов. Можно вообще не использовать стороннюю общую базу, а просто будут не связанные провайдеры. Но тогда это чистый парсинг.
И проблема тут в том, чтобы сделать его мало что универсальным, но и таким, чтобы его могли поддерживать в актуальном состоянии не специалисты (скриптовый метод + регулярные выражения).


![]() Kopa » 12.06.2023 21:03:05
Kopa » 12.06.2023 21:03:05
![]() delphius » 12.06.2023 21:47:14
delphius » 12.06.2023 21:47:14
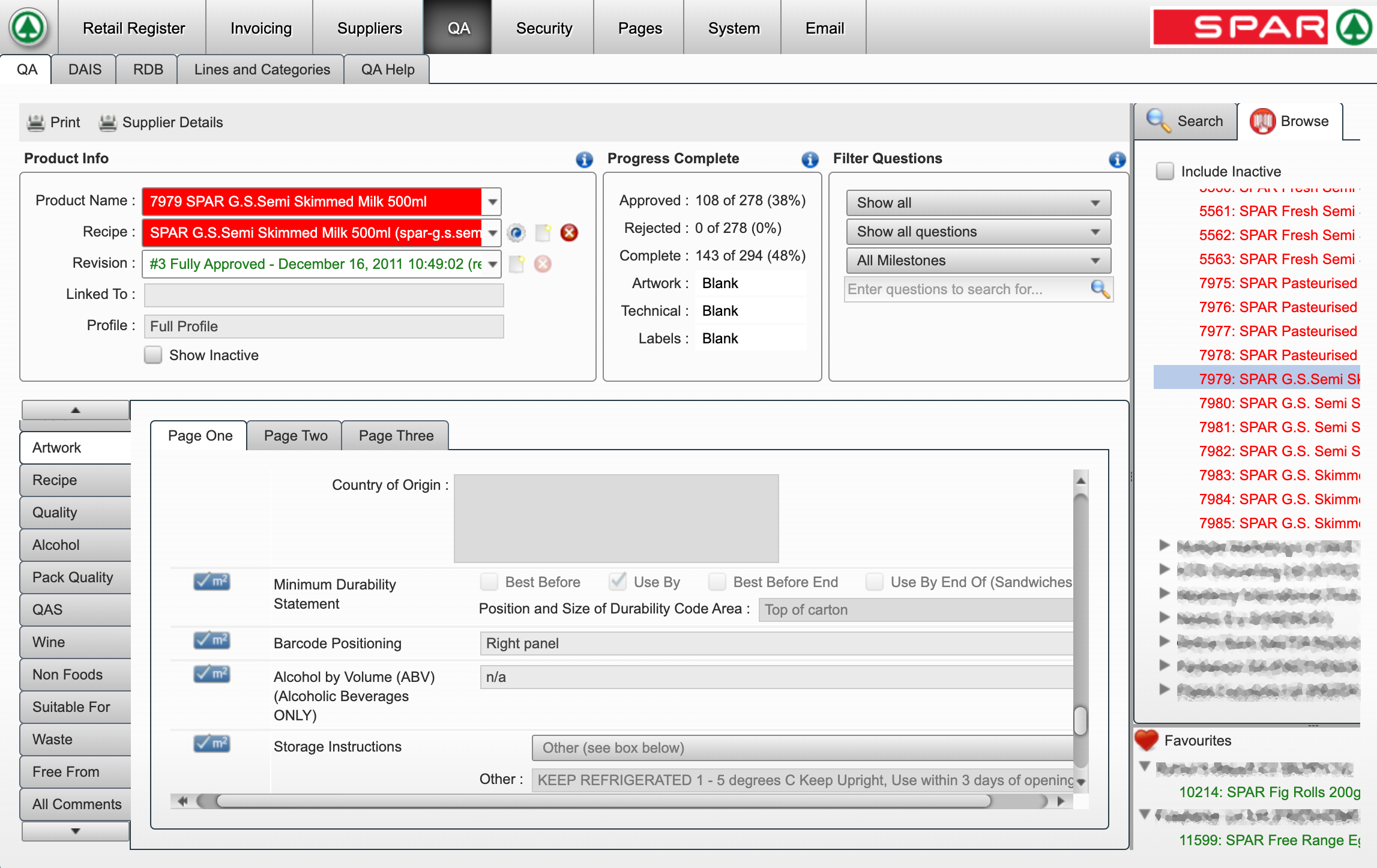
Kopa писал(а):библиотека Webui нормально собралась под Linux32 (Puppy Linux Xenial)
Kopa писал(а):примером редактора есть неувязки
Alex2013 писал(а):программная оболочка позволяет пользоваться контентом в более комфортной среде
films := Robot.FindElementsByXPath('//*[@id="dle-content"]/div[*]/div[1]/a/img');
paths := Robot.FindElementsByXPath('//*[@id="dle-content"]/div[*]/div[1]/a');![]() Alex2013 » 13.06.2023 09:26:43
Alex2013 » 13.06.2023 09:26:43
Вернуться в Сторонние средства
Сейчас этот форум просматривают: нет зарегистрированных пользователей и гости: 3
{kind=link}
{kind=link}